Your Brand Is Invisible to AI, and Regulators Are Still Sleeping
SOCi's 2026 Local Visibility Index found something alarming: many brands are far more visible in Google's local results than they are in AI answers.
For cannabis retailers, that gap matters because the category already has fragmented listings, age gates, state-specific rules, and uneven source quality.
That's not just a traffic problem. It's a brand erasure problem. And it's creating a regulatory vacuum that will explode in 18 months.
The Search-to-AI Gap Nobody Saw Coming
Cannabis retailers have spent three years mastering Google Local SEO. Treez, Weedmaps, and Google itself documented the playbook. Local citation consistency, reviews, NAP data, schema markup - all working. Dispensaries rank. People find them.
But Google Local and AI answer engines are fundamentally different distribution channels. Google returns your exact listing. ChatGPT generates recommendations from training data, web crawl patterns, and user feedback, and it's optimized for conversational answers, not local business directories.
SOCi's analysis, covering more than 350,000 locations across 2,751 brands, showed the gap clearly: local visibility in Google does not guarantee visibility in AI recommendations.
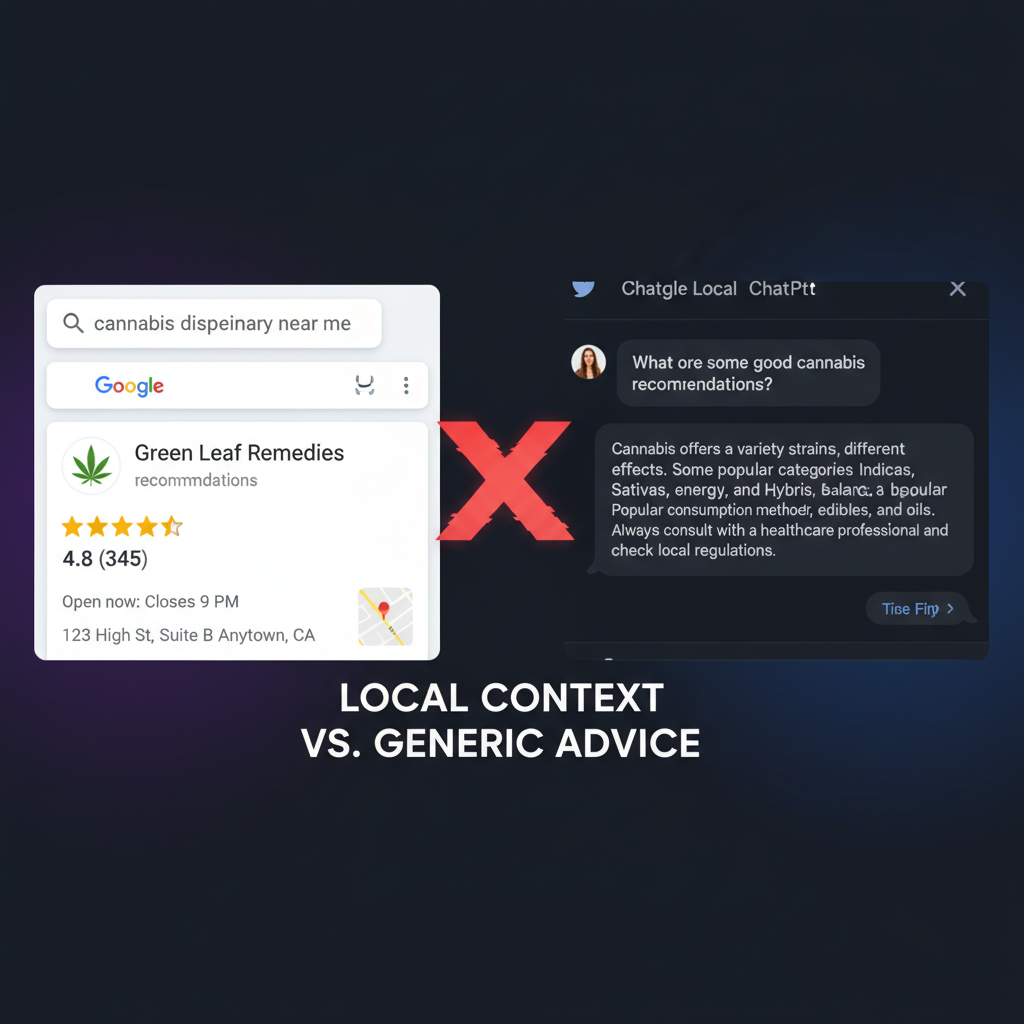
When your brand wins on Google but loses in AI, the data tells a different story.
Example: Search "dispensary near me" on Google, and you get your store with hours, reviews, location. Ask ChatGPT "where can I buy cannabis near [city]" and you either don't appear, or appear misattributed, or get lumped with competitors.
For cannabis, where brand differentiation is critical and regulatory compliance is non-negotiable, this visibility gap means:
- Lost customer discovery as more users ask AI systems for shortlists instead of browsing results
- Brand claim misrepresentation (AI answers can attribute competitor products to your dispensary)
- Zero data trail (you can't track what ChatGPT said about your brand yesterday)
- Regulatory exposure (if AI misattributes a compliance claim, who's liable?)
Why Cannabis Disappeared From AI Training Data
Cannabis content is tricky for LLM training. Most training data comes from publicly crawled web content, medical databases, regulatory documents, and user-generated content.
Problem #1: Local bias without web depth. Cannabis brands invest heavily in Google Local optimization but less in general web content that LLMs consume. Your Weedmaps listing ranks great. Your website might be thin. LLMs learn from diverse published content, not from directory citations.
Problem #2: Regulatory language as invisibility cloak. Cannabis brands must include mandatory disclaimers, age verification statements, and compliance copy. LLMs learn to deprioritize or skip pages that feel like "regulatory boilerplate." Your disclosures protect you legally but make you invisible to AI training algorithms.
Problem #3: Search engine weight vs training data weight. Google's algorithm favors brands with strong Local signals. LLMs were trained on diverse web content where Local listings don't carry the same weight as news articles, blog posts, and general web presence. Your Google optimization bought you a channel. It didn't buy you AI representation.
Result: Cannabis retail is well-represented on Google but underrepresented in LLM training, creating the visibility gap SOCi found.
The Compliance Time Bomb
Here's where this gets dangerous.
Cannabis regulators (California, Massachusetts, Colorado, Illinois) have not yet issued guidance on brand representation in AI answer engines. Why? Because regulators move slowly, and AI answer engines are new enough that enforcement hasn't caught up. But that window is closing fast.
Imagine this scenario: ChatGPT recommends "high-THC products for anxiety" and attributes a claim to Dispensary A that Dispensary A never made. Dispensary A sells high-CBD products for anxiety. A customer gets the wrong product, files a complaint with the state regulator.
The regulator asks: "Why did AI claim you sell high-THC for anxiety?"
Dispensary A answers: "We didn't control that content. An AI system generated it."
The regulator asks a harder question: "Can you prove what your official claims are, and can you show what you did when you found misleading claims in the market?"

Operators need dated records of what AI systems say about their brands.
This is already familiar from other uncontrolled channels. Cannabis regulators care about false product claims, even when the path from source to consumer is messy. AI answer engines are a new channel, and the liability framework is unclear.
The timing of enforcement is uncertain. The preparation work is not. Brands need a documented position before a complaint, audit, or plaintiff forces the issue.
This is not theoretical. The FTC is already using existing consumer-protection authority against deceptive AI claims. Cannabis regulators can apply the same basic logic to cannabis advertising and product claims.
What Cannabis Operators Can Do (Today)
The fix isn't simple, but it's actionable.
1. Audit your AI visibility. Search ChatGPT, Claude, and Perplexity for your brand name and products. Document what they say. Screenshot responses. This is your first data trail.
2. Build general web content (not just Local listings). LLMs weight diverse, published content higher than directory citations. Your blog post about your product lineup outweighs your Weedmaps listing in training data.
3. Claim and verify the sources AI systems read. Keep owned pages, local listings, directory profiles, and third-party mentions accurate. Be early before incorrect data becomes harder to unwind.
4. Document everything. Screenshot AI responses that mention your brand. Store them with timestamps. If a regulator asks, you have a record of what was said, and you can prove you didn't make those claims.
5. Prepare for AI disclosure rules. Start documenting your product claims now in a format regulators can audit. If disclosure rules tighten, you will already have the evidence base.
The Bigger Picture
This is a cannabis-specific version of a larger problem: brand visibility is fragmenting across discovery channels, and operators can't control or audit all of them. Like what happened with synthetic detection evasion in cannabis marketing (where AI-generated content started appearing unclaimed in user feeds), this trend will accelerate.
Search engines are one channel. Social media is another. AI answer engines are now a third and growing fast.
For regulated industries like cannabis, where every product claim carries compliance risk, this fragmentation is a liability multiplier. The brands that played it safe for years on Google Local got burned by regulators who didn't enforce those rules. The brands that move into AI answer engines now without documentation will get burned again.
The winners are the ones documenting their presence across all three channels today, before regulators make it mandatory.
Your dispensary might rank #1 on Google. That doesn't mean AI knows you exist. And when regulators start asking what claims are being made about your brand in AI systems (and they will), visibility gaps will cost you.
Start auditing your AI visibility now. It's not a marketing problem yet. But it will be a compliance problem in 18 months.
2026 evidence and control update
The more useful 2026 question is not whether cannabis brands are disappearing from ai answer engines is possible. It is whether regulated cannabis retail and marketing teams can prove what happened after the system made, shaped, ranked, routed, or explained a customer-facing decision.
The less obvious issue is that the hidden record is not only the customer-facing answer, it is the product data, state rule, age gate, claim boundary, and human owner behind that answer. That record is what separates a working AI pilot from a defensible operating system.
For source alignment, the public claim language should stay consistent with California Department of Cannabis Control retail guidance and FTC guidance on AI claims. Those sources do not remove the need for local legal review, but they give the article a better evidence spine than vendor screenshots or unsupported performance claims.
This also connects to related operating risk, AI measurement gap, compliance workflow, because the same pattern keeps repeating: AI systems look clean in the dashboard while the proof, ownership, and customer context live somewhere else.
| Control layer | What to verify | Evidence to keep |
|---|---|---|
| Source data | Which approved source fed the answer, recommendation, ranking, or claim | Source URL, vendor field, timestamp, and owner |
| Decision boundary | Where the AI is allowed to help and where it must stop | Allowed use case, blocked topics, and confidence threshold |
| Human review | Who owns the exception, correction, or escalation | Reviewer role, handoff note, and approval record |
| Monitoring | How the team catches drift, complaints, or weak signals | Review cadence, sampled outputs, and customer feedback themes |


Frequently asked questions
It is the difference between being visible in traditional search and being cited, named, or recommended by AI answer engines.
Google local results rely heavily on Google Business Profile, Maps, reviews, and local ranking signals. AI answer engines may use different source mixes, safety filters, and confidence thresholds.
Document prompts, AI responses, screenshots, dates, sources cited, incorrect claims, and any correction steps. This creates an evidence trail.
No. If AI systems repeat inaccurate product, location, age-gate, or effect claims, the issue can become compliance and legal risk.
Build stronger owned source material: location pages, product pages, compliance-safe FAQs, structured data, and consistent directory profiles.